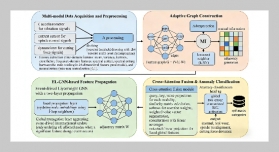
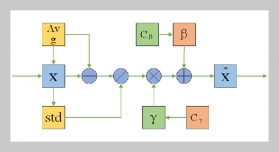
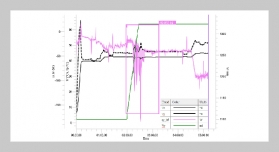
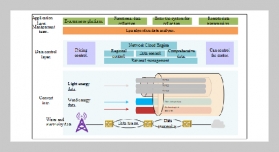
REFERENCES
- [1] Barak, A., Ben-Nun, T., Levy, E. and Shiloh, A., “A Package for Opencl Based Heterogeneous Computing on Clusters with Many GPU Devices,” Proc. of the 2010 IEEE International Conference on Cluster Computing Workshops and Posters, Heraklion, Greece, Sept. 20�24, pp. 1�7 (2010). doi: 10.1109/ CLUSTERWKSP.2010.5613086
- [2] Aoki, R., Oikawa, S., Tsuchiyama, R. and Nakamura, T., “Hybrid Opencl over High Speed Networks,” Proc. of the IEEE Region 10 Conference on TENCON 2010, Fukuoka, Japan, Nov. 21�24, pp. 1094�1099 (2010). doi: 10.1109/TENCON.2010.5686423
- [3] Kim, J., Kim, H., Lee, J. H. and Lee, J., “Achieving a Single Compute Device Image in Opencl for Multiple GPUs,” Proc. of the 16th ACM Symposium on Principles and Practice of Parallel Programming, New York, U.S.A., pp. 277�288 (2011). doi: 10.1145/1941553. 1941591
- [4] Duato, J., Igual, F. D., Mayo, R., Peña, A. J., QuintanaOrtí, E. S. and Silla, F., “An Efficient Implementation of Gpu Virtualization in High Performance Clusters,” Proc. of the 2009 International Conference on Parallel Processing, Berlin, Heidelberg, pp. 385�394 (2010). doi: 10.1109/ICPP.2011.58
- [5] Karunadasa, N. P. and Ranasinghe, D. N., “Accelerating High Performance Applications with CUDA And MPI,” Proc. of the 4th International Conference on Industrial and Information Systems 2009, Sri Lankapp, Dec. 28�31, pp. 331�336 (2009). doi: 10.1109/ ICIINFS.2009.5429842
- [6] nVidia, CUDA API Reference Manual, 4th ed., Nov. (2011).
- [7] Stevens, W. R., UNIX Network Programming, Vol. 2: Interprocess Communications, 2nd ed., Prentice Hall, New Jersey, pp. 399�450 (1998).
- [8] Aguilar, J. and Gelenbe, E., “Task Assignment and Transaction Clustering Heuristics for Distributed Systems,” Information Sciences: an International Journal - Special Issue: Load Balancing in Distributed Systems, Vol. 97, No. 1�2, pp. 199�219 (1997). doi: 10.1016/S0020-0255(96)00178-8
- [9] Woodside, C. M. and Monforton, G. G., “Fast Allocation of Processes in Distributed and Parallel Systems,” IEEE Transactions on Parallel and Distributed Systems, Vol. 4, No. 2, pp 164�174 (1993). doi: 10.1109/ 71.207592
- [10] Birrell, A. D. and Nelson, B. J., “Implementing Remote Procedure Calls,” ACM Transactions on Computer Systems, Vol. 2, No 1, pp. 39�59 (1984). doi:10.1145/2080.357392
- [11] ONC+ Developer’s Guide, Beta ed., Oracle Corporation, November (2010).
- [12] Wilbur, S. and Bacarisse, B., “Building Distributed Systems with Remote Call,” Software Engineering Journal, Vol. 2, No. 5, pp. 148�159 (1987). doi: 10.1049/sej.1987.0020
- [13] Kirk, D. B. and Hwu, W.-m. W., Programming Massively Parallel Processors: A Hands-on Approach, 1st ed., Morgan Kaufmann, San Francisco, pp. 110�116 (2010).
- [14] Kindratenko, V. V., Enos, J. J., Shi, G. C., Showerman, M. T., Arnold, G. W., Stone, J. E., Phillips, J. C. and Hwu, W.-m. W., “GPU Clusters for High-Performance Computing,” Proc. of 2009 IEEE International Conference on Cluster Computing, New Orleans, U.S.A., Aug. 31�Sept. 4, pp. 1�8 (2009). doi: 10.1109/ CLUSTR.2009.5289128
- [15] Kijsipongse, E. and U-ruekolan, S., “Dynamic Load Balancing on GPU Clusters for Large-Scale K-Means Clustering,” Proc. of 2012 International Joint Conference on Computer Science and Software Engineering, Bangkok, Thailand, May. 30�Jun. 1, pp. 346�350 (2012). doi: 10.1109/JCSSE.2012.6261977