Ching-Ming Chao This email address is being protected from spambots. You need JavaScript enabled to view it.1 , Po-Zung Chen2 and Chu-Hao Sun2 1Department of Computer Science and Information Management, Soochow University, Taipei, Taiwan 100, R.O.C.
2Department of Computer Science and Information Engineering, Tamkang University, Tamsui, Taiwan 251, R.O.C.
Received:
January 3, 2008
Accepted:
April 1, 2009
Publication Date:
September 1, 2009
Download Citation:
||https://doi.org/10.6180/jase.2009.12.3.11
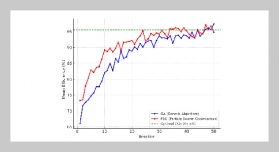
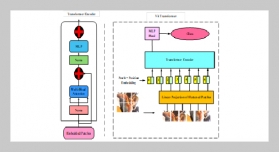
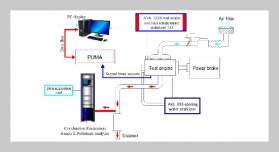
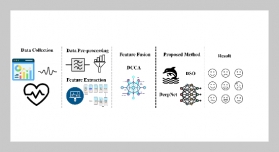
Data mining is the information technology that extracts valuable knowledge from large amounts of data. Due to the emergence of data streams as a new type of data, data streams mining has recently become a very important and popular research issue. There have been many studies proposing efficient mining algorithms for data streams. On the other hand, data mining can cause a great threat to data privacy. Privacy-preserving data mining hence has also been studied. In this paper, we propose a method for privacy-preserving classification of data streams, called the PCDS method, which extends the process of data streams classification to achieve privacy preservation. The PCDS method is divided into two stages, which are data streams preprocessing and data streams mining, respectively. The stage of data streams preprocessing uses the data splitting and perturbation algorithm to perturb confidential data. Users can flexibly adjust the data attributes to be perturbed according to the security need. Therefore, threats and risks from releasing data can be effectively reduced. The stage of data streams mining uses the weighted average sliding window algorithm to mine perturbed data streams. When the classification error rate exceeds a predetermined threshold value, the classification model is reconstructed to maintain classification accuracy. Experimental results show that the PCDS method not only can preserve data privacy but also can mine data streams accurately.ABSTRACT
Keywords:
Data Streams, Data Mining, Classification, Privacy Preservation, Incremental Mining
REFERENCES