




College of Music and Dance, Zhengzhou University of Science and Technology, Zhengzhou 450064 China
Received: April 5, 2026
Accepted: May 18, 2026
Publication Date: June 4, 2026
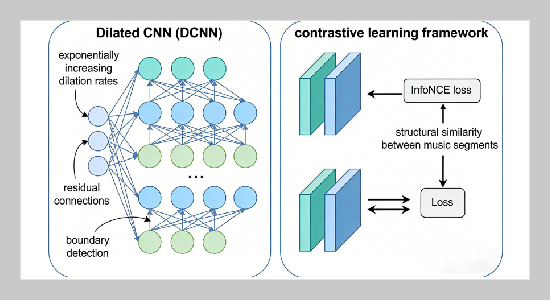
Detailed architectures of core modules
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | http://dx.doi.org/10.6180/jase.202609_32.068
Music structure analysis (MSA) and segmentation are fundamental tasks in music information retrieval (MIR), aiming to decompose music into semantically coherent segments (e.g., verse, chorus, bridge) and reveal hierarchical structural relationships. Traditional methods rely on handcrafted audio features (e.g., MFCC, chroma) and shallow models, which struggle to capture high-level semantic and temporal dependencies in complex music. This paper proposes a novel framework for intelligent music segmentation and structure analysis leveraging self-supervised audio representation learning. First, we pre-train a Transformer-based audio encoder on a large unlabeled music corpus via masked audio modeling (MAM) to learn general-purpose, semantically rich audio representations without labeled segmentation data. Then, we design a dual-branch structure analysis network: a segment boundary detection branch using a dilated convolutional neural network (DCNN) to locate segment boundaries, and a structural similarity clustering branch using contrastive learning to group segments with consistent semantic content. We further introduce a structural entropy-based optimization module to refine hierarchical structure trees, with the objective function formulated to balance boundary precision and structural consistency. Extensive experiments on three standard MSA datasets (RWC Pop, SALAMI, Beatles) demonstrate that our method outperforms state-of-the-art baselines by 6.2%−9.5% in F1-score for boundary detection and 5.8%-8.3% in normalized mutual information (NMI) for structural clustering.
Visualization results via t-SNE confirm that self-supervised representations capture meaningful musical structure, enabling robust cross-genre music analysis.
Keywords: Music structure analysis; Music segmentation; Self-supervised learning; Audio representation; Transformer; Contrastive learning; Structural entropy
- [1] O. Nieto, G. J. Mysore, C.-i. Wang, J. B. Smith, J. Schlüter, T. Grill, and B. McFee, (2020) “Audio-based music structure analysis: Current trends, open challenges, and applications” Transactions of the International Society for Music Information Retrieval 3(1): DOI: 10.5334/tismir.54.
- [2] M. Ahmed, U. Rozario, M. M. Kabir, Z. Aung, J. Shin, and M. F. Mridha, (2024) “Musical genre classification using advanced audio analysis and deep learning techniques” IEEE Open Journal of the Computer Society 5: 457–467. DOI: 10.1109/OJCS.2024.3431229.
- [3] Y. P. Pingle and L. K. Ragha, (2024) “An in-depth analysis of music structure and its effects on human body for music therapy” Multimedia Tools and Applications 83(15): 45715–45738. DOI: 10.1007/s11042-023-17290-w.
- [4] K. Bhandari and S. Colton. “Motifs, phrases, and beyond: The modelling of structure in symbolic music generation”. In: International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar). Springer. 2024, 33–51. DOI: 10.1007/978-3-031-56992-0_3.
- [5] J. Li, S. Soradi-Zeid, A. Yousefpour, and D. Pan, (2024) “Improved differential evolution algorithm based convolutional neural network for emotional analysis of music data” Applied Soft Computing 153: 111262. DOI: 10.1016/j.asoc.2024.111262.
- [6] D. Honnavalli and S. Shylaja. “Supervised machine learning model for accent recognition in English speech using sequential MFCC features”. In: International Conference on Artificial Intelligence and Data Engineering. Springer. 2019, 55–66. DOI: 10.1007/978-981-15-3514-7_5.
- [7] Y. Gao, X. Wang, X. Wang, Y. Tang, A. Jiang, and Y. Chen, (2026) “A Harmonic-Coupled Generative Adversarial Network for Speech Super-Resolution in Low Bandwidth Scenarios” IEEE Transactions on Audio, Speech and Language Processing 34: 1725–1735. DOI: 10.1109/TASLPRO.2026.3675815.
- [8] M. Jiang and S. Yin, (2023) “Facial expression recognition based on convolutional block attention module and multi-feature fusion” International journal of computational vision and robotics 13(1): 21–37. DOI: 10.1504/IJCVR.2023.127298.
- [9] Y. Guo, P. Huo, S. Huang, S. Liu, J. Luo, G. Gou, and Q. Li, (2026) “A Multichannel Flexible Interface for Environmental-Robust Laryngeal Signal Decoding” ACS Applied Materials & Interfaces 18(14): 20707–20718. DOI: 10.1021/acsami.6c01457.
- [10] B. Nataliia, T. Olena, and Y. Denys, (2026) “Analysis of the Correspondence Between DCT and Non-Classical Walsh-Hadamard Transforms for Code-Controlled Steganography” Journal of Telecommunication, Electronic and Computer Engineering (JTEC) 18(1): 9–17. DOI: 10.54554/jtec.2026.18.01.002.
- [11] F. Sabaz, Ü. Atila, M. Dörterler, and A. Uçan, (2026) “Challenges and enhancements in Turkish automatic lip reading using deep learning models” Signal, Image and Video Processing 20(4): 237. DOI: 10.1007/s11760-026-05252-2.
- [12] A. Mohanty and R. C. Cherukuri, (2026) “Whispered speech emotion recognition with gender detection using hybridopti-gendernet” Multimedia Tools and Applications 85(4): 318. DOI: 10.1007/s11042-026-21463-8.
- [13] I. Moummad, N. Farrugia, and R. Serizel. “Self-supervised learning for few-shot bird sound classification”. In: 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW). IEEE. 2024, 600–604. DOI: 10.1109/ICASSPW62465.2024.1062757.
- [14] B. Yang and X. Li, (2024) “Self-supervised learning of spatial acoustic representation with cross-channel signal reconstruction and multi-channel conformer” IEEE/ACM Transactions on Audio, Speech, and Language Processing 32: 4211–4225. DOI: 10.1109/TASLP.2024.3458811.
- [15] M. Buisson, B. McFee, S. Essid, and H. C. Crayencour, (2024) “Self-supervised learning of multi-level audio representations for music segmentation” IEEE/ACM Transactions on Audio, Speech, and Language Processing 32: 2141–2152. DOI: 10.1109/TASLP.2024.3379894.
- [16] S. V. Shayegh and C. Tadj, (2025) “Deep audio features and self-supervised learning for early diagnosis of neonatal diseases: sepsis and respiratory distress syndrome classification from infant cry signals” Electronics 14(2): 248. DOI: 10.3390/electronics14020248.
- [17] E. T. Ogidan, O. P. Olawale, and K. Dimililer. “Short-Time Fourier Transform in Audio Recognition Applications”. In: International Conference on Theory and Applications of Fuzzy Systems and Soft Computing. Springer. 2023, 171–177. DOI: 10.1007/978-3-031-72506-7_23.
- [18] L. Wang, H. Wang, S. Yin, and L. Wang, (2025) “Masked vision transformer for fast hyperspectral image classification” IEEE Transactions on Geoscience and Remote Sensing 63: DOI: 10.1109/TGRS.2025.3572242.
- [19] S. K. Sahu, S. K. Satapathy, S. K. Mohapatra, J. Heikkonen, R. Kanth, and T. K. Das, (2026) “A hybrid deep learning framework for sleep stage classification using single channel EEG signals” Discover Artificial Intelligence: DOI: 10.1007/s44163-026-01092-8.
- [20] S. Brenner and R. Sablatnig. “Subjective assessments of legibility in ancient manuscript images-the SALAMI dataset”. In: International Conference on Pattern Recognition. Springer. 2021, 68–82. DOI: 10.1007/978-3-030-68787-8_5.