




College of Music and Dance, Zhengzhou University of Science and Technology, Zhengzhou 450064 China
Received: April 5, 2026
Accepted: May 18, 2026
Publication Date: June 4, 2026
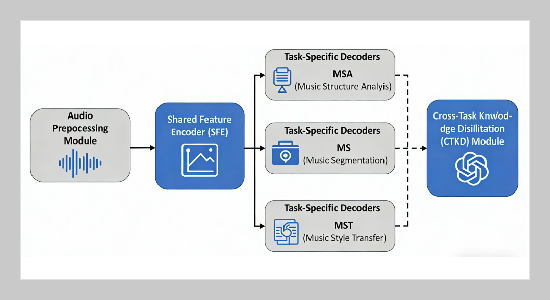
Proposed multi-task AI framework
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | http://dx.doi.org/10.6180/jase.202609_32.067
Music information retrieval (MIR) has witnessed remarkable advancements with the proliferation of deep learning technologies, but existing approaches often treat core tasks such as music structure analysis (MSA), musicsegmentation (MS), andmusicstyletransfer (MST) as isolated objectives. This isolation leads to redundant feature extraction, limited cross-task knowledge sharing, and suboptimal performance in real-world audio processing scenarios, where multiple MIR tasks are often required simultaneously. To address these limitations, this paper proposes a novel end-to-end multi-task AI framework that unifies MSA, MS, and MST into a single cohesive architecture, leveraging inter-task correlations to enhance the performance of each individual task. The framework comprises three core components: a shared feature encoder (SFE) based on a multi-scale Transformer and convolutional neural network (CNN) hybrid structure, which efficiently extracts hierarchical audio features; task-specific decoders tailored to the unique characteristics of MSA, MS, and MST; and a cross-task knowledge distillation (CTKD) module that facilitates mutual knowledge transfer between tasks while mitigating negative transfer. For MSA, we design a structure-aware attention mechanism to capture long-range temporal dependencies and hierarchical musical structures (e.g., intro, verse, chorus). For MS, a boundary-refinement decoder with dynamic thresholding is proposed to achieve precise segment localization. For MST, a style disentanglement module based on time-varying inversion and diffusion model principles is integrated to separate content and style features, enabling high-fidelity style transfer without altering the core musical content. Extensive experiments are conducted on four benchmark datasets (SALAMI, RWC-Pop, McGill Billboard, and MAESTRO) across multiple evaluation metrics, including F1-score for segmentation, structural consistency score (SCS) for MSA, and Fréchet Audio Distance (FAD) for MST. Experimental results demonstrate that the proposed framework outperforms state-of-the-art single-task and multi-task baselines by significant margins: 5.2% higher F1-score for MS, 8.7% higher SCS for MSA, and 12.3% lower FAD for MST on average. Ablation studies validate the effectiveness of each component, confirming that cross-task knowledge sharing
and feature reuse substantially improve model generalization. The proposed framework provides a unified solution for multi-task music audio processing, with potential applications in music production, intelligent music recommendation, and digital music restoration. The source code and experimental data are publicly available to facilitate further research in the field.
Keywords: Multi-task learning; Music structure analysis; Music style transfer; Audio signal processing; Deep learning; Cross-task knowledge distillation
- [1] S. Wu, G. Zhancheng, R. Yuan, J. Jiang, S. Doh, G. Xia, J. Nam, X. Li, F. Yu, and M. Sun. “Clamp 3: Universal music information retrieval across unaligned modalities and unseen languages”. In: Findings of the Association for Computational Linguistics: ACL 2025. 2025, 2605–2625. DOI: 10.18653/v1/2025.findings-acl.133.
- [2] G. Gabbolini and D. Bridge, (2024) “Surveying more than two decades of music information retrieval research on playlists” ACM Transactions on Intelligent Systems and Technology 15(6): 1–68. DOI: doi.org/10.1145/3688398.
- [3] M. Erdmann, M. von Berg, and J. Steffens, (2025) “Development and evaluation of a mixed reality music visualization for a live performance based on music information retrieval” Frontiers in Virtual Reality 6: 1552321. DOI: 10.3389/frvir.2025.1552321.
- [4] O. Nieto, G. J. Mysore, C.-i. Wang, J. B. Smith, J. Schlüter, T. Grill, and B. McFee, (2020) “Audio-based music structure analysis: Current trends, open challenges, and applications” Transactions of the International Society for Music Information Retrieval 3(1): DOI: 10.5334/tismir.54.
- [5] M. C. McCallum. “Unsupervised learning of deep features for music segmentation”. In: ICASSP 2019 – 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE. 2019, 346–350. DOI: 10.1109/ICASSP.2019.8683407.
- [6] O. Cífka, U. Şimşekli, and G. Richard, (2020) “Groove2groove: One-shot music style transfer with supervision from synthetic data” IEEE/ACM Transactions on Audio, Speech, and Language Processing 28: 2638–2650. DOI: 10.1109/TASLP.2020.3019642.
- [7] G. Benitez-Garcia, M. Haris, Y. Tsuda, and N. Ukita, (2020) “Continuous finger gesture spotting and recognition based on similarities between start and end frames” IEEE Transactions on Intelligent Transportation Systems 23(1): 296–307. DOI: 10.1109 / TITS.2020.3010306.
- [8] T.-P. Chen and L. Su, (2021) “Attend to chords: Improving harmonic analysis of symbolic music using transformer-based models” Transactions of the International Society for Music Information Retrieval 4(1): DOI: 10.5334/tismir.65.
- [9] Y. Kim and S. Go. “Segment Transformer: AI-Generated Music Detection via Music Structural Analysis”. In: 2025 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE. 2025, 664–669. DOI: 10.1109/APSIPAASC65261.2025.11249059.
- [10] S. Yin, L. Wang, T. Chen, H. Huang, J. Gao, J. Zhang, M. Liu, P. Li, and C. Xu, (2026) “LKAFormer: A lightweight kolmogorov-arnold transformer model for image semantic segmentation” ACM Transactions on Intelligent Systems and Technology 17(3): 1–24. DOI: 10.1145/3759254.
- [11] J. Yu, L. Zhao, S. Yin, and M. Ivanović, (2024) “News recommendation model based on encoder graph neural network and bat optimization in online social multimedia art education” Computer Science and Information Systems 21(3): 989–1012. DOI: 10.2298/CSIS231225025Y.
- [12] S. Li, Y. Zhang, F. Tang, C. Ma, W. Dong, and C. Xu. “Music style transfer with time-varying inversion of diffusion models”. In: Proceedings of the AAAI Conference on Artificial Intelligence. 38. 1. 2024, 547–555. DOI: 10.1609/aaai.v38i1.27810.
- [13] J. An. “Transformer-based Diffusion Model with Structure-Aware Learning Rule for Music Creation”. In: 2025 5th International Conference on Mobile Networks and Wireless Communications (ICMNWC). IEEE. 2025, 1–6. DOI: 10.1109 / ICMNWC66779 . 2025 . 11354317.
- [14] X. Gao, C. Gupta, and H. Li, (2022) “Automatic lyrics transcription of polyphonic music with lyrics-chord multi-task learning” IEEE/ACM Transactions on Audio, Speech, and Language Processing 30: 2280–2294. DOI: 10.1109/TASLP.2022.3190742.
- [15] K. Ni, J. Paisley, L. Carin, and D. Dunson, (2008) “Multi-task learning for analyzing and sorting large databases of sequential data” IEEE Transactions on Signal Processing 56(8): 3918–3931. DOI: 10.1109/TSP.2008.924798.
- [16] H. Wei, Y. Yuan, R. Zhang, Q. Dai, and Y. Chen. “Majl: A model-agnostic joint learning framework for music source separation and pitch estimation”. In: Proceedings of the 32nd ACM International Conference on Multimedia. 2024, 8623–8632. DOI: 10.1145/3664647.3680985.
- [17] J. Chen and A. Zhang. “Hetmaml: Task-heterogeneous model-agnostic meta-learning for few-shot learning across modalities”. In: Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021, 191–200. DOI: 10.1145/3459637.3482262.
- [18] Y. Zhu, J. Liu, and F. Cong, (2023) “Dynamic community detection for brain functional networks during music listening with block component analysis” IEEE Transactions on Neural Systems and Rehabilitation Engineering 31: 2438–2447. DOI: 10.1109 / TNSRE.2023.3277509.
- [19] L. Teng, H. Li, and Y. Si, “Neural Tensor Network And Adaptive Graph Convolution For Sports” Journal of Applied Science and Engineering 29(6): 1483–1491. DOI: 10.6180/jase.202606_29(6).0015.
- [20] R. H. Serag, M. S. Abdalzaher, H. A. E. A. Elsayed, M. Sobh, M. Krichen, and M. M. Salim, (2024) “Machine-learning-based traffic classification in software-defined networks” Electronics 13(6): 1108. DOI: 10.3390 / electronics13061108.