




Wu Lixian1, Lai Weiwei2, Bu li1, Lin Yujie1, Wu Guangcai2, and Zheng Yinglong2
1Foshan Power Supply Bureau of Guangdong Power Grid Co., Ltd., Foshan 528000, Guangdong, China
2Guangdong Electric Power Information Technology Co., Ltd., Guangzhou 510062, Guangdong, China
Received: March 25, 2026
Accepted: April 28, 2026
Publication Date: May 27, 2026
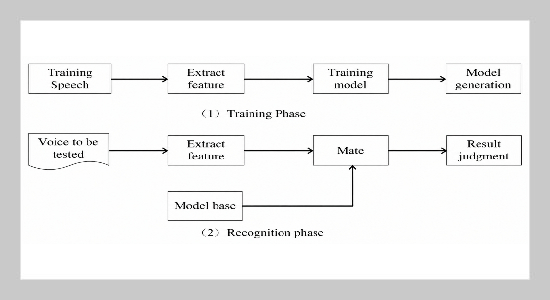
Speech recognition framework diagram
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | http://dx.doi.org/10.6180/jase.202609_32.057
Speech recognition is one of the important technologies of biological information recognition, which can extract the corresponding characteristics through language recognition, so as to recognize the generated speech. The International Institute of Technology (National Institute of Standards and Technology) evaluated speech recognition technology and found that the Probabilistic Linear Discriminant (PLDA), Analysis) model was good However, in practice, speech recognition is easily affected by external factors such as environmental noise and human voice, leading to differences between registered and test speech and making data processing difficult. These challenges limit its application. To address issues of time length variation and limited training samples, this study applies and refines a PLDA-based probabilistic correction model by adjusting its distribution using speech data. Finally, the PLDA parameters obtained by the training are taken as the test value, and the hydrodynamic simulation software is used to improve the performance of speech recognition. Hydrodynamic simulation enhances the PLDA model’s robustness by addressing speech duration and cross-domain variability, leading to improved recognition accuracy. Experiments demonstrate notable gains in both EER and DCF metrics. It is found that the speech recognition method based on PLDA model can effectively improve the recognition function after hydrodynamic simulation, solve the problems of time length mismatch and limited training samples, and provide a theoretical basis for the application of PLDA model in speech recognition.
Keywords: PLDA model; speech recognition; hydrodynamic simulation; cross-domain migration
- [1] H. Lauren, (2023) “Incorporating Automatic Speech Recognition Methods into the Transcription of Police-Suspect Interviews: Factors Affecting Automatic Performance” Frontiers in Communication 8: DOI: 10.3389/fcomm.2023.1165233.
- [2] Z. Dong, Q. Ding, W. Zhai, and M. Zhou, (2023) “A Speech Recognition Method Based on Domain-Specific Datasets and Confidence Decision Networks” Sensors 23(13): DOI: 10.3390/s23136036.
- [3] H. Wang, Z. Li, D. Song, X. He, and M. Khan, (2022) “Applying Machine Learning and Automatic Speech Recognition for Intelligent Evaluation of Coal Failure Probability under Uniaxial Compression” Minerals 12(12): 1548. DOI: 10.3390/min12121548.
- [4] J. Wu, Y. Zhang, L. Xie, Y. Yan, X. Zhang, S. Liu, X. An, E. Yin, and D. Ming, (2022) “A Novel Silent Speech Recognition Approach Based on Parallel Inception Convolutional Neural Network and Mel Frequency Spectral Coefficient” Frontiers in Neurorobotics 16: 971446. DOI: 10.3389/fnbot.2022.971446.
- [5] M. Amini, D. Matrouf, J. F. Bonastre, S. Dowerah, R. Serizel, and D. Jouvet. “Learning Noise Robust ResNet-Based Speaker Embedding for Speaker Recognition”. In: Proceedings of Odyssey: The Speaker and Language Recognition Workshop. 2022. DOI: 10.21437/Odyssey.2022-6.
- [6] E. H. Alkhammash, M. Hadjouni, and A. M. Elshewey, (2022) “A Hybrid Ensemble Stacking Model for Gender Voice Recognition Approach” Electronics 11(11): 1750. DOI: 10.3390/electronics11111750.
- [7] J. Heeren, T. Nuesse, M. Latzel, I. Holube, V. Hohmann, K. C. Wagener, and M. Schulte, (2022) “The Concurrent OLSA Test: A Method for Speech Recognition in Multi-talker Situations at Fixed SNR” Trends in Hearing 26: 23312165221108257. DOI: 10.1177/23312165221108257.
- [8] K. Zhao and D. Wang, (2021) “Research on Speech Recognition Method in Multi-Layer Perceptual Network Environment” International Journal of Circuits, Systems and Signal Processing 15: 996–1004. DOI: 10.46300/9106.2021.15.107.
- [9] J. Guglani and A. Mishra, (2020) “Automatic Speech Recognition System with Pitch-Dependent Features for Punjabi Language on KALDI Toolkit” Applied Acoustics 167: DOI: 10.1016/j.apacoust.2020.107386.
- [10] Y. H. Tu, J. Du, and C. H. Lee, (2019) “Speech Enhancement Based on Teacher–Student Deep Learning Using Improved Speech Presence Probability for Noise-Robust Speech Recognition” IEEE/ACM Transactions on Audio, Speech, and Language Processing 27(12): 2080–2091. DOI: 10.1109/TASLP.2019.2940662.
- [11] H. B. Prasetio, H. Tamura, and K. Tanno, (2019) “Generalized Discriminant Methods for Improved X-Vector Back-end Based Stress Speech Recognition” IEEJ Transactions on Electronics, Information and Systems 139(11): 1341–1347. DOI: 10.1541/ieejeiss.139.1341.
- [12] T. N. Sainath, R. J. Weiss, K. W. Wilson, A. Narayanan, and M. Bacchiani. “Learning the Speech Front-End with Raw Waveform CLDNNs”. In: Interspeech. 2015, 1–5. DOI: 10.21437/Interspeech.2015-1.
- [13] S. Cumani, O. Plchot, and P. Laface. “Probabilistic Linear Discriminant Analysis of i-Vector Posterior Distributions”. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2013, 7644–7648. DOI: 10.1109/ICASSP.2013.6639150.
- [14] J. Guglani and A. Mishra, (2020) “Automatic Speech Recognition System with Pitch-Dependent Features for Punjabi Language on KALDI Toolkit” Applied Acoustics 167: DOI: 10.1016/j.apacoust.2020.107386.
- [15] S. H. Grandhi and M. M. Kamruzzaman, (2024) “Automatic Stutter Speech Recognition and Classification Using Hyper-Heuristic Search Algorithm” International Journal of Automation and Smart Technology 14(1): DOI: 10.5875/at.dm761m36.
- [16] X. Chen, X. Liu, Y. Wang, A. Ragni, J. H. Wong, and M. J. Gales, (2019) “Exploiting Future Word Contexts in Neural Network Language Models for Speech Recognition” IEEE/ACM Transactions on Audio, Speech, and Language Processing 27(9): 1444–1454. DOI: 10.1109/TASLP.2019.2922048.
- [17] Y. Zhang, P. Zhang, and Y. Yan, (2019) “Language Model Score Regularization for Speech Recognition” Chinese Journal of Electronics 28(3): 604–609. DOI: 10.1049/cje.2019.03.015.
- [18] C. Li, H. Ge, and G. Chen. “A Robust Speech Feature Extraction Method Based on Nonlinear Power Transform Gammachirp Filter”. CN109256127B. 2021.
- [19] N. Brümmer, A. Swart, L. Mošner, A. Silnova, O. Plchot, T. Stafylakis, and L. Burget, (2022) “Probabilistic Spherical Discriminant Analysis: An Alternative to PLDA for Length-Normalized Embeddings” arXiv preprint: DOI: 10.48550/arXiv.2203.14893.
- [20] B. Priyanka and S. I. A., (2018) “A Probabilistic Feature-Based SVM Model for Hindi/English Speech Recognition” International Journal of Engineering & Technology 7(2.8): 271. DOI: 10.14419/ijet.v7i2.8.10423.
- [21] V. R. Raman and G. J. Vysotsky. “Methods and Apparatus for Generating and Using Garbage Models for Speaker Dependent Speech Recognition Purposes”. US5842165A. 1998.
- [22] Y. Jeong, (2013) “Speaker Adaptation Using Probabilistic Linear Discriminant Analysis for Continuous Speech Recognition” Electronics Letters 49(25): 1641–1643. DOI: 10.1049/el.2013.2223.
- [23] C. Zhang, B. H. Roh, and G. Shan. “Poster: Dynamic Clustered Federated Framework for Multi-Domain Network Anomaly Detection”. In: Companion of the 19th International Conference on Emerging Networking Experiments and Technologies. 2023, 71–72. DOI: 10.1145/3624354.3630086.