




College of Information Science and Engineering, Liuzhou Institute of Technology, Liuzhou 545616, Guangxi, China
Received: October 25, 2025
Accepted: May 8, 2026
Publication Date: May 21, 2026
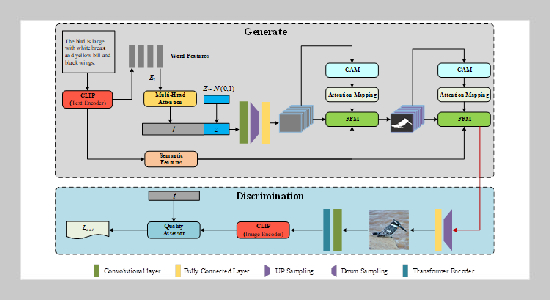
Structure of CLIP-CA-GAN
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | http://dx.doi.org/10.6180/jase.202609_32.052
Targeting the issues of weak fine-grained alignment capability and insufficient semantic controllability in existing generative adversarial network approaches, this paper presents a multimodal fusion-based model, namely Contrastive Language–Image Pretraining-Cross-Attention-Generative Adversarial Networks (CLIP CA-GAN). With GAN as the basic architecture, this model incorporates the Contrastive Language-Image Pretraining (CLIP) model to establish multimodal semantic constraints. It dynamically fuses the local features of text and images via the Cross-Attention Mechanism (CAM), and optimizes generation quality through a designed Feature Fusion Module and a comprehensive loss function (LF). Experimental results demonstrate that the performance of CLIP-CA-GAN outperforms mainstream methods. On MS-COCO, the Fréchet Inception Distance (FID) decreases to 16.09, and the Inception Score (IS) rises to 4.91. On CUB, the FID stands at 14.06, the IS at 5.33, and the R–precision (RP) reaches 79.24. Additionally, the model has a relatively small number of parameters and high training efficiency, thus providing a high-quality and low-complexity solution for image generation.
Keywords: CLIP-CA-GAN, multimodal, CLIP, fine-grained alignment, CAM
- [1] F. Bie, Y. Yang, Z. Zhou, A. Ghanem, M. Zhang, Z. Yao, X. Wu, C. Holmes, P. Golnari, D. A. Clifton, et al., (2024) “Renaissance: A survey into ai text-to-image generation in the era of large model” IEEE transactions on pattern analysis and machine intelligence 47(3): 2212–2231. DOI: 10.1109/TPAMI.2024.3522305.
- [2] V. Paananen, J. Oppenlaender, and A. Visuri, (2024) “Using text-to-image generation for architectural design ideation” International Journal of Architectural Computing 22(3): 458–474. DOI: 10.1177/14780771231222783.
- [3] J. Oppenlaender. “The cultivated practices of text-to-image generation”. In: Humane Autonomous Technology: Re-thinking Experience with and in Intelligent Systems. Springer, 2024, 325–349. DOI: 10.1007/978-3-031-66528-8_14.
- [4] L. Höllein, A. Božič, N. Müller, D. Novotny, H.-Y. Tseng, C. Richardt, M. Zollhöfer, and M. Nießner. “Viewdiff: 3d-consistent image generation with text-to-image models”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024, 5043–5052. URL: https://openaccess.thecvf.com/content/CVPR2024/html/Hollein_ViewDiff_3D-Consistent_Image_Generation_with_Text-to-Image_Models_CVPR_2024_paper.html.
- [5] J. Gartner and M. Romanov, (2024) “The advantages of ai text to image generation” International Journal of Art, Design, and Metaverse 2(1): 1–8. DOI: https://topazart.info/e-journals/index.php/ijam/article/view/65.
- [6] A. Dunkel, D. Burghardt, and M. Gugulica, (2024) “Generative text-to-image diffusion for automated map production based on geosocial media data” KN-Journal of Cartography and Geographic Information 74(1): 3–15. DOI: 10.1007/s42489-024-00159-9.
- [7] A. A. Laghari, V. V. Estrela, and S. Yin, (2024) “How to collect and interpret medical pictures captured in highly challenging environments that range from nanoscale to hyperspectral imaging” Current Medical Imaging 20(1): e28122212228. DOI: 10.2174/1573405619666221228094228.
- [8] S. Narasimhaswamy, U. Bhattacharya, X. Chen, I. Dasgupta, S. Mitra, and M. Hoai. “Handiffuser: Text-to-image generation with realistic hand appearances”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, 2468–2479. URL: https://openaccess.thecvf.com/content/CVPR2024/html/Narasimhaswamy_HanDiffuser_Text-to-Image_Generation_With_Realistic_Hand_Appearances_CVPR_2024_paper.html.
- [9] A. A. Laghari, Y. Sun, M. Alhussein, K. Aurangzeb, M. S. Anwar, and M. Rashid, (2023) “Deep residual-dense network based on bidirectional recurrent neural network for atrial fibrillation detection” Scientific reports 13(1): 15109. DOI: 10.1038/s41598-023-40343-x.
- [10] A. A. Laghari, S. Shahid, R. Yadav, S. Karim, A. Khan, H. Li, and Y. Shoulin, (2023) “The state of art and review on video streaming” Journal of High Speed Networks 29(3): 211–236. DOI: 10.3233/JHS-222087.
- [11] M. A. Munir, R. A. Shah, M. Ali, A. A. Laghari, A. Almadhor, and T. R. Gadekallu, (2024) “Enhancing gene mutation prediction with sparse regularized autoencoders in lung cancer radiomics analysis” IEEE Access 13: 7407–7425. DOI: 10.1109/ACCESS.2024.3523330.
- [12] S. Karim, Y. Zhang, A. A. Laghari, and M. R. Asif. “Image processing based proposed drone for detecting and controlling street crimes”. In: 2017 IEEE 17th International Conference on Communication Technology (ICCT). IEEE. 2017, 1725–1730. DOI: 10.1109/ICCT.2017.8359925.
- [13] U. Saeed, K. Kumar, M. A. Khuhro, A. A. Laghari, A. A. Shaikh, and A. Rai, (2024) “DeepLeukNet—A CNN based microscopy adaptation model for acute lymphoblastic leukemia classification” Multimedia Tools and Applications 83(7): 21019–21043. DOI: 10.1007/s11042-023-16191-2.
- [14] G. Marcus, E. Davis, and S. Aaronson, (2022) “A very preliminary analysis of DALL-E 2” arXiv preprint arXiv:2204.13807: DOI: 10.48550/arXiv.2204.13807.
- [15] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. “High-resolution image synthesis with latent diffusion models”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, 10684–10695. URL: https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html?utm_source=rns.dwaiat.de.
- [16] H. Li and X.-J. Wu, (2024) “CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach” Information Fusion 103: 102147. DOI: 10.1016/j.inffus.2023.102147.
- [17] R. Tamilkodi, K. Suryakala, N. Vamsi, M. Arvind Reddy, M. Nithin Kumar, and M. Venkat. “Transforming text into art: Exploring dall-e’s text-to-image generation capabilities”. In: International Conference on Smart Data Intelligence. Springer. 2024, 413–421. DOI: 10.1007/978-981-97-3191-6_31.
- [18] Y. Shi, M. Shang, and Z. Qi, (2023) “Intelligent layout generation based on deep generative models: A comprehensive survey” Information Fusion 100: 101940. DOI: 10.1016/j.inffus.2023.101940.
- [19] S. Naveen, M. S. R. Kiran, M. Indupriya, T. Manikanta, and P. Sudeep, (2021) “Transformer models for enhancing AttnGAN based text to image generation” Image and Vision Computing 115: 104284. DOI: 10.1016/j.imavis.2021.104284.
- [20] L. Yan, R. Yan, B. Chai, G. Ceng, P. Zhou, and J. Gao, (2024) “DM-GAN: CNN hybrid vits for training GANs under limited data” Pattern Recognition 156: 110810. DOI: 10.1016/j.patcog.2024.110810.
- [21] R. Mehmood, R. Bashir, and K. J. Giri. “Comparative Analysis of AttnGAN, DF-GAN and SSA-GAN”. In: 2021 3rd International Conference on Advances in Computing, Communication Control and Networking (ICAC3N). IEEE. 2021, 370–375. DOI: 10.1109/ICAC3N53548.2021.9725424.
- [22] D. S. Patra and S. Padhee. “Comparative Analysis of ControlGAN and ControlGAN-GP Models based Text-to-Image Synthesis”. In: 2022 OITS International Conference on Information Technology (OCIT). IEEE. 2022, 564–568. DOI: 10.1109/OCIT56763.2022.00110.
- [23] W. Liao, K. Hu, M. Y. Yang, and B. Rosenhahn. “Text to image generation with semantic-spatial aware gan”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, 18187–18196. URL: https://openaccess.thecvf.com/content/CVPR2022/html/Liao_Text_to_Image_Generation_With_Semantic-Spatial_Aware_GAN_CVPR_2022_paper.html.
- [24] S. Hou, Z. Li, K. Wu, Y. Zhao, and H. Li, (2024) “Masked cross-attention and multi-channel attention guiding single-stage generative adversarial networks for text-to-image generation” The Visual Computer 40(12): 8639–8651. DOI: 10.1007/s00371-024-03260-2.
- [25] S. A. Baumann, F. Krause, M. Neumayr, N. Stracke, M. Sevi, V. T. Hu, and B. Ommer. “Continuous, subject-specific attribute control in t2i models by identifying semantic directions”. In: Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, 13231–13241. DOI: https://openaccess.thecvf.com/content/CVPR2025/html/Baumann_Continuous_Subject-Specific_Attribute_Control_in_T2I_Models_by_Identifying_Semantic_CVPR_2025_paper.html.
- [26] K. Huang, K. Sun, E. Xie, Z. Li, and X. Liu, (2023) “T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation” Advances in Neural Information Processing Systems 36: 78723–78747. URL: https://proceedings.neurips.cc/paper_files/paper/2023/file/f8ad010cdd9143dbb0e9308c093aff24-Paper-Datasets_and_Benchmarks.pdf.
- [27] T. Hu, L. Li, J. Van de Weijer, H. Gao, F. S. Khan, J. Yang, M.-M. Cheng, K. Wang, and Y. Wang, (2024) “Token merging for training-free semantic binding in text-to-image synthesis” Advances in Neural Information Processing Systems 37: 137646–137672. DOI: 10.52202/079017-4372.
- [28] N. S. Mudiraj and S. Singh, (2025) “Semantic mapping of Hindi text-to-image generation using CUB dataset” Scientific Reports 15(1): 36632. DOI: 10.1038/s41598-025-20537-1.
- [29] O. Durusoy et al., (2025) “Open-source datasets for image processing and artificial intelligence research: A comparison of imagenet and ms coco datasets” Int. J. Sci. Innov. Eng 2: 639–653. DOI: 10.70849/IJSCI20250202575.
- [30] J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans, (2022) “Cascaded diffusion models for high fidelity image generation” Journal of Machine Learning Research 23(47): 1–33. URL: http://jmlr.org/papers/v23/21-0635.html.
- [31] S. Ramzan, M. M. Iqbal, and T. Kalsum, (2022) “Text-to-image generation using deep learning” Engineering Proceedings 20(1): 16. DOI: 10.3390/engproc2022020016.