




Received: April 8, 2026
Accepted: May 1, 2026
Publication Date: May 17, 2026
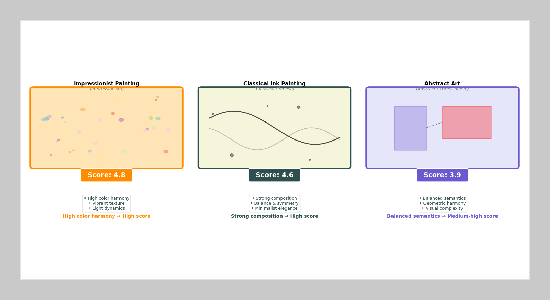
Qualitative Aesthetic Score Prediction on Sample Artworks
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | http://dx.doi.org/10.6180/jase.202609_32.043
Automated quantitative aesthetic evaluation of visual artworks is a challenging cross-disciplinary task involving computer vision and art history. Traditional aesthetic assessment methods rely on handcrafted features or single-branch deep learning models, which fail to comprehensively capture the multi-faceted artistic attributes (e.g., color harmony, composition balance, texture, and semantic style) and long-range global dependencies critical to artistic appreciation. To address these limitations, this paper proposes a novel framework: Vision Transformer with Multi-Dimensional Artistic Feature Fusion (MDAF-ViT). Our model integrates a hierarchical Vision Transformer (ViT) backbone for global context modeling with multi-branch feature extractors to capture low-level visual attributes, mid-level compositional rules, and high-level semantic style features. A key innovation is the Dynamic Multi-Dimensional Attention Fusion (MDAF) module, which adaptively weights and fuses heterogeneous artistic features. Extensive experiments on standard art aesthetic datasets (BAID, APDDv2, JenAesthetics) demonstrate that MDAF-ViT significantly outperforms state-of-the-art CNN and ViT based methods, achieving superior performance in terms of Pearson Linear Correlation Coefficient (PLCC), Spearman Rank Correlation Coefficient (SRCC), and Mean Squared Error (MSE). This work provides a robust, interpretable foundation for large-scale digital art analysis and curation.
Keywords: Computational Aesthetics; Artwork Evaluation; Vision Transformer
- [1] D. Jonauskaite, N. Dael, L. Baboulaz, L. Chèvre, I. Cierny, N. Ducimetière, A. Fekete, P. Gabioud, H. Leder, M. Vetterli, et al., (2024) “Interactive digital engagement with visual artworks and cultural artefacts enhances user aesthetic experiences in the laboratory and museum” International Journal of Human–Computer Interaction 40(6): 1369–1382. DOI: 10.1080/10447318.2022.2143767.
- [2] E. Stamkou, D. Keltner, R. Corona, E. Aksoy, and A. S. Cowen, (2024) “Emotional palette: A computational mapping of aesthetic experiences evoked by visual art” Scientific Reports 14(1): 19932. DOI: 10.1038/s41598-024-69686-9.
- [3] E. A. Vessel and H. Ovadia, (2025) “The role of the default mode network in aesthetic appeal” Current Opinion in Behavioral Sciences 66: 101608. DOI: 10.1016/j.cobeha.2025.101608.
- [4] T. Shi, C. Chen, X. Li, and A. Hao, (2024) “Semantic and style based multiple reference learning for artistic and general image aesthetic assessment” Neurocomputing 582: 127434. DOI: 10.1016/j.neucom.2024.127434.
- [5] X. Zhang, Y. Xiao, J. Peng, X. Gao, and B. Hu, (2024) “Confidence-based dynamic cross-modal memory network for image aesthetic assessment” Pattern Recognition 149: 110227. DOI: 10.1016/j.patcog.2023.110227.
- [6] X. Lu, Z. Lin, H. Jin, J. Yang, and J. Z. Wang, (2015) “Rating image aesthetics using deep learning” IEEE Transactions on Multimedia 17(11): 2021–2034. DOI: 10.1109/TMM.2015.2477040.
- [7] H. Jang and J.-S. Lee, (2021) “Analysis of deep features for image aesthetic assessment” IEEE Access 9: 29850–29861. DOI: 10.1109/ACCESS.2021.3060171.
- [8] J. McCormack and A. Lomas. “Understanding aesthetic evaluation using deep learning”. In: International conference on computational intelligence in music, sound, art and design (part of EvoStar). Springer. 2020, 118–133. DOI: 10.1007/978-3-030-43859-3_9.
- [9] X. Tian, Z. Dong, K. Yang, and T. Mei, (2015) “Query-dependent aesthetic model with deep learning for photo quality assessment” IEEE Transactions on Multimedia 17(11): 2035–2048. DOI: 10.1109/TMM.2015.2479916.
- [10] Y. Deng, C. C. Loy, and X. Tang, (2017) “Image aesthetic assessment: An experimental survey” IEEE Signal Processing Magazine 34(4): 80–106. DOI: 10.1109/MSP.2017.2696576.
- [11] Y. Ke, Y. Wang, K. Wang, F. Qin, J. Guo, and S. Yang, (2023) “Image aesthetics assessment using composite features from transformer and CNN” Multimedia Systems 29(5): 2483–2494. DOI: 10.1007/s00530-023-01141-7.
- [12] M. Carrasco, C. González-Martín, J. Aranda, and L. Oliveros, (2026) “Vision Transformer attention alignment with human visual perception in aesthetic object evaluation” Plos one 21(4): e0344006. DOI: 10.1371/journal.pone.0344006.
- [13] S. Li, H. Liang, M. Xie, and X. He. “Multi-scale and multi-patch aggregation network based on dual-column vision fusion for image aesthetics assessment”. In: 2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE. 2024, 1–6. DOI: 10.1109/ICME57554.2024.10687850.
- [14] H. Takimoto, F. Omori, and A. Kanagawa, (2021) “Image aesthetics assessment based on multi-stream CNN architecture and saliency features” Applied Artificial Intelligence 35(1): 25–40. DOI: 10.1080/08839514.2020.1839197.
- [15] D. Soydaner and J. Wagemans, (2024) “Multi-task convolutional neural network for image aesthetic assessment” Ieee Access 12: 4716–4729. DOI: 10.1109/ACCESS.2024.3349961.
- [16] C.-H. Lee, J.-L. Shih, W.-L. Su, C.-C. Lien, and C.-C. Han. “Combination of Global Maximum Pooling and Local Average Pooling for Unsupervised Fine-Grained Image Retrieval”. In: Proceedings of the 2024 7th Artificial Intelligence and Cloud Computing Conference. 2024, 299–307. DOI: 10.1145/3719384.3719427.
- [17] J. Yao, J. Yao, Y. Yang, and C. Huang. “Hierarchical Adaptive Position Encoding-Based Transformer for Point Cloud Analysis”. In: International Conference on Neural Information Processing. Springer. 2024, 197–210. DOI: 10.1007/978-981-96-6576-1_14.
- [18] R. Egele, J. Junior, J. CS, J. N. van Rijn, I. Guyon, X. Baró, A. Clapés, P. Balaprakash, S. Escalera, T. Moeslund, et al., (2024) “Ai competitions and benchmarks: Dataset development” arXiv preprint arXiv:2404.09703: DOI: 10.48550/arXiv.2404.09703.
- [19] U. Lee, Y. Son, J. Shin, G. Byun, Y. Lee, J. Koh, M. Jeon, and H. Kim. “LLaVA-Docent-V2: Improving Data Quality and Pedagogical Data Generation to Train Large Multimodal Models for Art Appreciation Education”. In: International Conference on Intelligent Tutoring Systems. Springer. 2025, 213–228. DOI: 10.1007/978-3-031-98284-2_17.
- [20] S. A. Amirshahi, G. U. Hayn-Leichsenring, J. Denzler, and C. Redies. “Jenaesthetics subjective dataset: analyzing paintings by subjective scores”. In: European Conference on Computer Vision. Springer. 2014, 3–19. DOI: 10.1007/978-3-319-16178-5_1.