




1Weifang Vocational College, Weifang 262737 China
2Shandong Vocational College of Information Technology, Weifang 261061 China
Received: February 7, 2026
Accepted: April 1, 2026
Publication Date: April 30, 2026
Mass Loss Due to Impact Velocity
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | http://dx.doi.org/10.6180/jase.202609_32.020
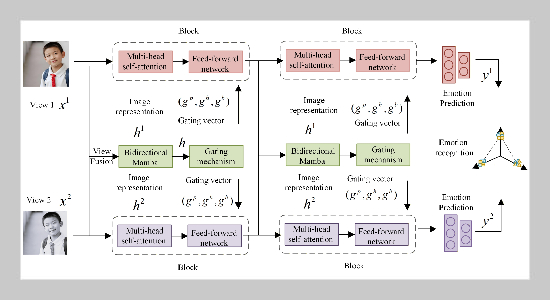
Accurate emotion recognition for university students is essential for mental health monitoring and engagement analysis, yet the intensive computational cost of standard Vision Transformers hinders their deployment on resource-constrained edge devices. To address this challenge, we propose an Efficient Multi-view Transformer (EFFormer) designed for real-time affective computing in campus environments. EFFormer first employs a Bidirectional Mamba strategy to synthesize unified affective representations from multiple views, effectively capturing complex cross-view correlations with linear complexity. Furthermore, we introduce an instance specific adaptive gating mechanism that dynamically executes patch pruning, attention head activation, and transformer block skipping based on the complexity of each input sample. By jointly optimizing the backbone with a resource-aware loss function and utilizing Gumbel-Softmax reparameterization, EFFormer achieves a superior trade-off between recognition accuracy and inference efficiency. Experimental results demonstrate that our framework significantly reduces computational overhead and latency while maintaining high-fidelity emotional state recognition, providing a practical and robust solution for intelligent emotion monitoring in
university settings.
Keywords: Multi-view Transformer; emotion recognition; efficient and effective inference
- [1] W. Zhang and J. Wang, (2024) “English text sentiment analysis network based on CNN and U-Net” IFS/ACM Transactions on Machine Learning 1(1): 13–18. DOI: 10.70891/JSE.2024.100009.
- [2] M. Liu, Y. Li, Z. Chen, and Y. Lin, (2026) “Information-Driven Complementarity and Consistency Mining for Multi-View Clustering” IEEE Signal Processing Letters 33: 216–220. DOI: 10.1109/LSP.2025.3639380.
- [3] A. Xiang, Z. Qi, H. Wang, Q. Yang, and D. Ma. “A multimodal fusion network for student emotion recognition based on transformer and tensor product”. In: 2024 IEEE 2nd International Conference on Sensors, Electronics and Computer Engineering (ICSECE). 2024, 1–4. DOI: 10.1109/ICSECE61636.2024.10729485.
- [4] J. Gao, M. Liu, P. Li, A. A. Laghari, A. R. Javed, N. Victor, and T. R. Gadekallu, (2024) “Deep Incomplete Multiview Clustering via Information Bottleneck for Pattern Mining of Data in Extreme-Environment IoT” IEEE Internet of Things Journal 11(16): 26700–26712. DOI: 10.1109/JIOT.2023.3325272.
- [5] J. Gao, M. Liu, P. Li, J. Zhang, and Z. Chen, (2024) “Deep Multiview Adaptive Clustering With Semantic Invariance” IEEE Transactions on Neural Networks and Learning Systems 35(9): 12965–12978. DOI: 10.1109/TNNLS.2023.3265699.
- [6] Y. Wang, R. Huang, S. Song, Z. Huang, and G. Huang, (2021) “Not all images are worth 16×16 words: Dynamic transformers for efficient image recognition” Advances in neural information processing systems 34: 11960–11973.
- [7] X. Zhang, M. Li, S. Lin, H. Xu, and G. Xiao, (2023) “Transformer-based multimodal emotional perception for dynamic facial expression recognition in the wild” IEEE Transactions on Circuits and Systems for Video Technology 34(5): 3192–3203. DOI: 10.1109/TCSVT.2023.3312858.
- [8] D. Kim and B. C. Song. “Emotion-aware multi-view contrastive learning for facial emotion recognition”. In: European Conference on Computer Vision. 2022, 178–195. DOI: 10.1007/978-3-031-19778-9_11.
- [9] J. Chen, S. Dey, L. Wang, N. Bi, and P. Liu, (2024) “Attention-based multi-modal multi-view fusion approach for driver facial expression recognition” IEEE Access: DOI: 10.1109/ACCESS.2024.3462352.
- [10] Y.-J. Cui, X.-H. Liu, J. Liang, and Y.-M. Fu. “Mvgt: A multi-view graph transformer based on spatial relations for eeg emotion recognition”. In: International Conference on Neural Information Processing. 2025, 3–17. DOI: 10.1007/978-981-95-4378-6_1.
- [11] Y. Wei, S. Yuan, R. Yang, L. Shen, Z. Li, L. Wang, and M. Chen. “Tackling modality heterogeneity with multi-view calibration network for multimodal sentiment detection”. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023, 5240–5252. DOI: 10.18653/v1/2023.acl-long.287.
- [12] X.-B. Nguyen, H.-T. Nguyen, T.-H. Nguyen, N.-T. Do, and Q. V. Dinh. “Emotic masked autoencoder on dual-views with attention fusion for facial expression recognition”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, 4784–4792. DOI: 10.1109/CVPRW63382.2024.00481.
- [13] G. Hou, Y. Shen, W. Zhang, W. Xue, and W. Lu. “Enhancing emotion recognition in conversation via multi-view feature alignment and memorization”. In: Findings of the association for computational linguistics: EMNLP 2023. 2023, 12651–12663. DOI: 10.18653/v1/2023.findings-emnlp.842.
- [14] L. Yuan, Y. Chen, T. Wang, W. Yu, Y. Shi, Z.-H. Jiang, F. E. Tay, J. Feng, and S. Yan. “Tokens-to-token vit: Training vision transformers from scratch on imagenet”. In: Proceedings of the IEEE/CVF international conference on computer vision. 2021, 558–567. DOI: 10.1109/ICCV48922.2021.00060.
- [15] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo. “Swin transformer: Hierarchical vision transformer using shifted windows”. In: Proceedings of the IEEE/CVF international conference on computer vision. 2021, 10012–10022. DOI: 10.1007/s11042-024-19615-9.
- [16] Y. Li, K. Zhang, J. Cao, R. Timofte, M. Magno, L. Benini, and L. Van Goo. “LocalViT: Analyzing locality in vision transformers”. In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 2023, 9598–9605. DOI: 10.1109/IROS55552.2023.10342025.
- [17] Z. Zhan, X. Mao, H. Liu, and S. Yu, (2025) “STGL: Self-Supervised Spatio-Temporal Graph Learning for Traffic Forecasting” Journal of Artificial Intelligence Research 2(1): 1–8. DOI: 10.70891/JAIR.2025.040001.
- [18] W. Liu, (2024) “Channel Reorganization for Few-Shot Segmentation” Journal of Artificial Intelligence Research 1(1): 36–40. DOI: 10.70891/JAIR.2024.100025.