




Lijuan Feng, Jiangjiang Li, Yachao Zhang, and Yandong Han
School of Electronics and Electrical Engineering, Zhengzhou University of Science and Technology, Zhengzhou 450064 China
Received: June 25, 2025
Accepted: August 15, 2025
Publication Date: April 2, 2026
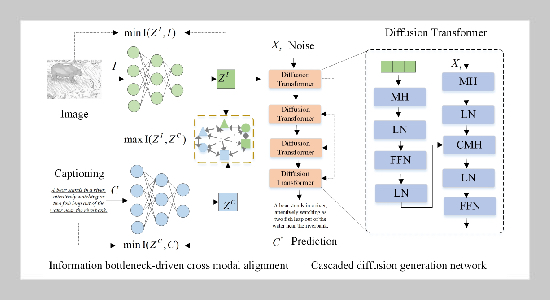
The overall architecture of IBA-CD. It contains an information bottleneck-driven cross modal alignment and a cascaded diffusion generation network.
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | https://doi.org/10.6180/jase.202605_29(5).0016
Deep learning has revolutionized cross-modal understanding through its ability to process heterogeneous visual-textual data, which achieves encouraging performance in the image captioning domain. However, existing methods struggle with redundant cross-modal representations and autoregressive generation bottle necks, leading to semantically misaligned captions. To address these challenges, an innovative data-driven cartoon image captioning framework (IBA-CD) is proposed through two synergistic advancements. First, IBA-CD develops an information bottleneck-driven cross-modal alignment mechanism that fusing principles from information theory and deep learning, to optimize semantic distillation. Such a mechanism suppresses redundant visual-textual mutual information while maximizing task-relevant correlations through variational inference. Second, IBA-CD pioneers a cascaded diffusion generation paradigm that reimagines text synthesis through bidirectional Transformer-based denoising processes, establishing non-autoregressive generation with multi-stage visual-semantic refinement. IBA-CD achieves component synergy through a bidirectional closed loop mechanism: The information bottleneck alignment dynamically injects distilled compact semantic features as conditional guidance into each denoising step of the diffusion network, enabling fine-grained visual-textual alignment through cross-modal attention mechanisms. Simultaneously, quality feedback from the generation process proactively optimizes the feature alignment intensity, forming an iterative refinement cycle that evolves from semantic compression to generation correction. This collaborative framework ultimately accomplishes efficient and precise cross-modal reasoning through tightly coupled visual-semantic distillation and progressive generative enhancement. Extensive experiments on benchmark datasets verify significant improvements in the cartoon image captioning task.
Keywords: Image captioning; information bottleneck alignment; cascaded diffusion network
- [1]J.Prudviraj,C.Vishnu,and C.K.Mohan,(2022)”M-FFN:multi-scale feature fusion network for image captioning”Applied Intelligence 52(13):14711–14723.DOI:10.1007/s10489-022-03463-x.
- [2]C.-W.Kuo and Z.Kira.”Haav:Hierarchical aggregation of augmented views for image captioning”.In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.2023,11039–11049.
- [3]Y.Hu,H.Hua,Z.Yang,W.Shi,N.A.Smith,and J.Luo,(2022)”Promptcap:Prompt-guided task-aware image captioning”arXiv preprint arXiv:2211.09699:DOI:10.48550/arXiv.2211.09699.
- [4]J.Gao,P.Li,A.A.Laghari,G.Srivastava,T.R.Gadekallu,S.Abbas,and J.Zhang,(2024)”Incomplete multiview clustering via semidiscrete optimal transport for multimedia data mining in IoT”ACM Transactions on Multimedia Computing,Communications and Applications 20(6):1–20.DOI:10.1145/3625548.
- [5]J. Gao, M. Liu, P. Li, A.A.Laghari,A.R.Javed,N.Victor,and T.R.Gadekallu,(2023)”Deep Incomplete Multiview Clustering via Information Bottleneck for Pattern Mining of Data in Extreme-Environment IoT”IEEE Internet of Things Journal 11(16):26700–26712.DOI:10.1109/JIOT.2023.3325272.
- [6]J.Gao,M.Liu,P.Li,J.Zhang,and Z.Chen,(2024)”Deep Multiview Adaptive Clustering With Semantic Invariance”IEEE Transactions on Neural Networks and Learning Systems 35(9):12965–12978.DOI:10.1109/TNNLS.2023.3265699.
- [7]J.Hessel,A.Holtzman,M.Forbes,R.Le Bras,and Y.Choi.”CLIPScore:A Reference-free Evaluation Metric for Image Captioning”.In:EMNLP(1).2021.DOI:10.48550/arXiv.2104.08718.
- [8]D.Xu,W.Zhao,Y.Cai,and Q.Huang.”Zero-textcap:Zero-shot framework for text-based image captioning”.In:Proceedings of the 31st ACM International Conference on Multimedia.2023,4949–4957.DOI:10.1145/3581783.3612571.
- [9]J.Luo,Y.Li,Y.Pan,T.Yao,J.Feng,H.Chao,and T.Mei.”Semantic-conditional diffusion networks for image captioning”.In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.2023,23359–23368.
- [10]R.Ramos,B.Martins,D.Elliott,and Y.Kementchedjhieva.”Smallcap:lightweight image captioning prompted with retrieval augmentation”.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2023,2840–2849.
- [11]J.Li,D.M.Vo,A.Sugimoto,and H.Nakayama.”Evcap:Retrieval-augmented image captioning with external visual-name memory for open-world comprehension”.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2024,13733–13742.
- [12]Y.Luo,J.Ji,X.Sun,L.Cao,Y.Wu,F.Huang,C.-W.Lin,and R.Ji.”Dual-level collaborative transformer for image captioning”.In:Proceedings of the AAAI conference on artificial intelligence.35.3.2021,2286–2293.DOI:10.1609/aaai.v35i3.16328.
- [13]B.Liu,D.Wang,X.Yang,Y.Zhou,R.Yao,Z.Shao,and J.Zhao.”Show,deconfound and tell:Image captioning with causal inference”.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.2022,18041–18050.
- [14]Z.Zhan,X.Mao,H.Liu,and S.Yu,(2025)”STGL:Self-Supervised Spatio-Temporal Graph Learning for Traffic Forecasting”Journal of Artificial Intelligence Research 2(1):1–8.DOI:10.70891/JAIR.2025.040001.
- [15]W.Zhang and J.Wang,(2024)”English Text Sentiment Analysis Network based on CNN and U-Net”Journal of Science and Engineering 1(1):13–18.DOI:10.70891/JSE.2024.100009.
- [16]J.Zhang,L.Jain,Y.Guo,J.Chen,K.Zhou,S.Suresh,A.Wagenmaker,S.Sievert,T.T.Rogers,K.G.Jamieson,etal.,(2024)”Humor in ai:Massive scale crowd-sourced preferences and benchmarks for cartoon captioning”Advances in Neural Information Processing Systems 37:125264–125286.
- [17]K.Tanaka,K.Uehara,L.Gu,Y.Mukuta,and T.Harada.”Content-Specific Humorous Image Captioning Using Incongruity Resolution Chain-of-Thought”.In:Findings of the Association for Computational Linguistics:NAACL 2024.2024,2348–2367.DOI:10.18653/v1/2024.findings-naacl.152.