




Xianlei Ge1,2, Xiaobo Shen1,3, and Yingxuan Zhou1
1School of Electronic Engineering, Huainan Normal University, Huainan 232038, China
2College of Computing and Information Technologies, National University, Manila 1008, Philippines
3College of Industrial Education, Technological University of the Philippines, Manila 1000, Philippines
Received: January 6, 2024
Accepted: December 18, 2024
Publication Date: April 6, 2026
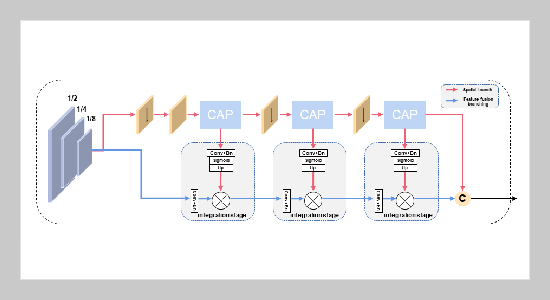
Overall structure of the Localized Compressed Feature (LFCE) capture module. It contains a spatial branch (red), a semantic feature fusion branch (blue), and symbols representing element multiplication.
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | http://dx.doi.org/10.6180/jase.202510_28(10).0009
In recent years, with the gradual progress of automatic driving technology, semantic segmentation of road scenes, as the core of this technology, has become a hot spot of research. However, nowadays, most of the convolutional (CNN)-based methods appear to be inefficient and costly due to the factors of large amount of detection data and complex structure. It limits their performance in dealing with some fast response (real-time) tasks. Addressing the above problems, this paper proposes a capsule network-based semantic segmentation method for road images, which achieves a good balance between recognition efficiency and detection speed. Specifically, the DDC-Net designed based on capsule network is used as the baseline network, and different connection paths are dynamically selected according to pixel affinity during forward propagation. In addition, DDC-S and DDC-G are designed for spatial detail fusion and semantic fusion, respectively, and the local feature extraction module (LFCE) is designed using a two-branch structure. Numerous experiments show that the method described in this paper outperforms most of the current CNN-based methods in terms of model size, recognition flexibility and overall performance. In ADE20K and Cityscapes test datasets, the method described in this paper achieves 74.5% and 79.4% mean intersection and merger ratio (mIoU) accuracies at 63.9fps and 64.8fps, and the experimental results demonstrate the effectiveness of our method.
Keywords: image semantic segmentation; deep learning; autonomous driving; road scene detection; fast response
- [1] Y. Guo, Y. Liu, T. Georgiou, and M. S. Lew, (2018) “A review of semantic segmentation using deep neural networks” International journal of multimedia information retrieval 7: 87–93. DOI: 10.1007/s13735-017-0141-z.
- [2] Y. Xu, M. Li, L. Cui, S. Huang, F. Wei, and M. Zhou. “Layoutlm: Pre-training of text and layout for document image understanding”. In: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2020, 1192–1200. DOI: 10.1145/3394486.3403172.
- [3] H. Shao, L. Wang, R. Chen, H. Li, and Y. Liu. “Safetyenhanced autonomous driving using interpretable sensor fusion transformer”. In: Conference on Robot Learning. PMLR. 2023, 726–737. DOI: 10.48550/arXiv.2207.14024.
- [4] L. Hou, Y. Cheng, N. Shazeer, N. Parmar, Y. Li, P. Korfiatis, T. M. Drucker, D. J. Blezek, and X. Song. High Resolution Medical Image Analysis with Spatial Partitioning. 2019. DOI: 10.48550/arXiv.1909.03108.arXiv: 1909.03108 [eess.IV].
- [5] Y. Yao, M. Xu, C. Choi, D. J. Crandall, E. M. Atkins, and B. Dariush. “Egocentric Vision-based Future Vehicle Localization for Intelligent Driving Assistance Systems”. In: 2019 International Conference on Robotics and Automation (ICRA). 2019, 9711–9717. DOI: 10.1109/ICRA.2019.8794474.
- [6] E. Shelhamer, J. Long, and T. Darrell, (2017) “Fully Convolutional Networks for Semantic Segmentation” IEEE Transactions on Pattern Analysis and Machine
Intelligence 39(4): 640–651. DOI: 10.1109/TPAMI.2016.2572683. - [7] J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang, and H. Lu. “Dual Attention Network for Scene Segmentation”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019. DOI: 10.1109/CVPR.2019.00326.
- [8] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. “Pyramid Scene Parsing Network”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017. DOI: 10.1109/CVPR.2017.660.
- [9] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, (2018) “DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs” IEEE Transactions on Pattern Analysis and Machine Intelligence 40(4): 834–848. DOI: 10.1109/TPAMI.2017.2699184.
- [10] H. Huang, L. Lin, R. Tong, H. Hu, Q. Zhang, Y. Iwamoto, X. Han, Y.-W. Chen, and J. Wu. “UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation”. In: ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2020, 1055–1059. DOI: 10.1109/ICASSP40776.2020.9053405.
- [11] H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia. “ICNet for Real-Time Semantic Segmentation on HighResolution Images”. In: Proceedings of the European Conference on Computer Vision (ECCV). 2018. DOI: 10.48550/arXiv.1704.08545.
- [12] C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang. “BiSeNet: Bilateral Segmentation Network for Realtime Semantic Segmentation”. In: Proceedings of the European Conference on Computer Vision (ECCV). 2018. DOI: 10.1007/978-3-030-01261-8_20.
- [13] A. Paszke, A. Chaurasia, S. Kim, and E. Culurciello. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. 2016. DOI: 10.48550/arXiv.1606.02147. arXiv: 1606.02147 [cs.CV].
- [14] X. Ding, C. Xia, X. Zhang, X. Chu, J. Han, and G. Ding. RepMLP: Re-parameterizing Convolutions into Fullyconnected Layers for Image Recognition. 2022. DOI: 10.48550/arXiv.2105.01883. arXiv: 2105.01883 [cs.CV].
- [15] G. Bender, H. Liu, B. Chen, G. Chu, S. Cheng, P.-J. Kindermans, and Q. V. Le. “Can Weight Sharing Outperform Random Architecture Search? An Investigation With TuNAS”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020. DOI: 10.1109/CVPR42600.2020.01433.
- [16] Y. Chen, W. Li, and L. Van Gool. “ROAD: Reality Oriented Adaptation for Semantic Segmentation of Urban Scenes”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018. DOI: 10.1109/CVPR.2018.00823.
- [17] J. Sun and Y. Li, (2021) “Multi-feature fusion network for road scene semantic segmentation” Computers & Electrical Engineering 92: 107155. DOI: 10.1016/j.compeleceng.2021.107155.
- [18] H. Pan, Y. Hong, W. Sun, and Y. Jia, (2023) “Deep Dual-Resolution Networks for Real-Time and Accurate Semantic Segmentation of Traffic Scenes” IEEE Transactions on Intelligent Transportation Systems 24(3): 3448–3460. DOI: 10.1109/TITS.2022.3228042.
- [19] L. Sun, K. Yang, X. Hu, W. Hu, and K. Wang, (2020) “Real-Time Fusion Network for RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-Driving Images” IEEE Robotics and Automation Letters 5(4): 5558–5565. DOI: 10.1109/LRA.2020.3007457.
- [20] M. Orsic, I. Kreso, P. Bevandic, and S. Segvic. “In Defense of Pre-Trained ImageNet Architectures for Real-Time Semantic Segmentation of Road-Driving Images”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019. DOI: 10.1109/CVPR.2019.01289.
- [21] H. Zhang, C. Wu, Z. Zhang, Y. Zhu, H. Lin, Z. Zhang, Y. Sun, T. He, J. Mueller, R. Manmatha, M. Li, and A. Smola. “ResNeSt: Split-Attention Networks”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2022, 2736–2746. DOI: 10.1109/CVPRW56347.2022.00309.
- [22] B. Cheng, M. D. Collins, Y. Zhu, T. Liu, T. S. Huang, H. Adam, and L.-C. Chen. “Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020. DOI: 10.1109/CVPR42600.2020.01249.
- [23] S. Borse, Y. Wang, Y. Zhang, and F. Porikli. “InverseForm: A Loss Function for Structured BoundaryAware Segmentation”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021, 5901–5911. DOI: 10.1109/CVPR46437.2021.00584.
- [24] Z. Chen, Y. Duan, W. Wang, J. He, T. Lu, J. Dai, and Y. Qiao. Vision Transformer Adapter for Dense Predictions. 2023. DOI: 10.48550/arXiv.2205.08534. arXiv: 2205.08534 [cs.CV].
- [25] E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo. “SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers”. In: Advances in Neural Information Processing Systems. Ed. by M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan. 34. Curran Associates, Inc., 2021, 12077–12090. DOI: 10.48550/arXiv.2105.15203.
- [26] D. Bashkirova, M. Abdelfattah, Z. Zhu, J. Akl, F. Alladkani, P. Hu, V. Ablavsky, B. Calli, S. A. Bargal, and K. Saenko. “ZeroWaste Dataset: Towards Deformable Object Segmentation in Cluttered Scenes”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022, 21147–21157. DOI: 10.1109/CVPR52688.2022.02047.
- [27] S. Sabour, N. Frosst, and G. E. Hinton. “Dynamic Routing Between Capsules”. In: Advances in Neural Information Processing Systems. Ed. by I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett. 30. Curran Associates, Inc., 2017. DOI: 10.48550/arXiv.1710.09829.
- [28] V. Mazzia, F. Salvetti, and M. Chiaberge, (2021) “Efficient-capsnet: Capsule network with self-attention routing” Scientific reports 11(1): 14634. DOI: 10.1038/s41598-021-93977-0.
- [29] J. Rajasegaran, V. Jayasundara, S. Jayasekara, H. Jayasekara, S. Seneviratne, and R. Rodrigo. “DeepCaps: Going Deeper With Capsule Networks”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019. DOI: 10.1109/CVPR.2019.01098.
- [30] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. MobileNets: Efficient Convolutional Neural Networks for
Mobile Vision Applications. 2017. DOI: 10.48550/arXiv.1704.04861. arXiv: 1704.04861 [cs.CV]. - [31] A. Kirillov, Y. Wu, K. He, and R. Girshick. “PointRend: Image Segmentation As Rendering”. In: Proceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR). 2020. DOI: 10.1109/CVPR42600.2020.00982. - [32] L. Reiher, B. Lampe, and L. Eckstein. “A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a
Semantically Segmented Image in Bird’s Eye View”. In: 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC). 2020, 1–7. DOI: 10.1109/ITSC45102.2020.9294462. - [33] M. Yang, K. Yu, C. Zhang, Z. Li, and K. Yang. “DenseASPP for Semantic Segmentation in Street Scenes”. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018. DOI: 10.1109/CVPR.2018.00388.
- [34] T. Takikawa, D. Acuna, V. Jampani, and S. Fidler. “Gated-SCNN: Gated Shape CNNs for Semantic Segmentation”. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2019. DOI: 10.1109/ICCV.2019.00533.
- [35] J. Lee, D. Kim, J. Ponce, and B. Ham. “SFNet: Learning Object-Aware Semantic Correspondence”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019. DOI: 10.1109/CVPR.2019.00238.
- [36] R. P. K. Poudel, S. Liwicki, and R. Cipolla. Fast-SCNN: Fast Semantic Segmentation Network. 2019. DOI: 10.48550/arXiv.1902.04502. arXiv: 1902.04502 [cs.CV].
- [37] E. Romera, J. M. Álvarez, L. M. Bergasa, and R. Arroyo, (2018) “ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation” IEEE Transactions on Intelligent Transportation Systems 19(1): 263–272. DOI: 10.1109/TITS.2017.2750080.
- [38] Z. Guo, Z. Chen, T. Yu, J. Chen, and S. Liu. “Progressive Image Inpainting with Full-Resolution Residual Network”. In: Proceedings of the 27th ACM International Conference on Multimedia. MM ’19. Nice, France: Association for Computing Machinery, 2019, 2496–2504. DOI: 10.1145/3343031.3351022.
- [39] S. Wang, L. Yi, Q. Chen, Z. Meng, H. Dong, and Z. He. “Edge-aware Fully Convolutional Network with CRF-RNN Layer for Hippocampus Segmentation”. In: 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC). 2019, 803–806. DOI: 10.1109/ITAIC.2019.8785801.
- [40] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. “Pyramid scene parsing network”. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, 2881–2890. DOI: 10.48550/arXiv.1612.01105.
- [41] H. Wang, X. Jiang, H. Ren, Y. Hu, and S. Bai. “SwiftNet: Real-Time Video Object Segmentation”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021, 1296–1305. DOI: 10.1109/CVPR46437.2021.00135.
- [42] H. Li, P. Xiong, H. Fan, and J. Sun. “DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation”. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019. DOI: 10.1109/CVPR.2019.00975.
- [43] S. Yan, C. Wu, L. Wang, F. Xu, L. An, K. Guo, and Y. Liu. “DDRNet: Depth Map Denoising and Refinement for Consumer Depth Cameras Using Cascaded CNNs”. In: Proceedings of the European Conference on Computer Vision (ECCV). 2018. DOI: 10.1007/978-3-030-01249-6_10.