




Haiyun Ma1 and Zhonglin Zhang2
1School of Electronic Information and Electrical Engineering, Tianshui Normal University, Tianshui, 741001, China
2School of Electronic and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China
Received: June 25, 2025
Accepted: August 3, 2025
Publication Date: April 2, 2026
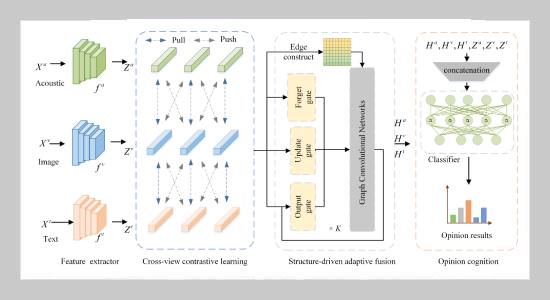
The overall architecture of SMOM. Given a social media conversation X with the acoustic view Xa, the image view Xv and text view Xt, SMOM utilizes view-specific feature extractors to learn the corresponding representations Za, Zv, and
Zt, respectively. Then, SMOM performs the cross-view contrastive learning between view-specific representations. Meanwhile, SMOM utilizes the structure-driven adaptive fusion function to obtain the corresponding fusion representations Ha, Hv, and Ht, respectively. Finally, SMOM leverages the classifier to obtain the opinions of each user.
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
Download Citation: BibTeX | https://doi.org/10.6180/jase.202604_29(4).0016
As the importance of public engagement monitoring grows in the face of complex social challenges, analyzing social media data from multiple perspectives has become crucial for understanding diverse public sentiments. Current methods often fall short in effectively supporting decision-making due to their inability to dynamically adapt to the evolving nature of social media discussions. They rely on static strategies that fail to capture the intricate correlations between features across different views, making it difficult to identify sentiment patterns that emerge through complex dependencies in user-generated content. To address these shortcomings, we propose a novel deep multi-view contrastive fusion network (SMOM) designed for comprehensive public opinion monitoring in social media. SMOM features a view-specific feature extractor that captures inherent information within each view. It then employs cross-view contrastive learning to maximize mutual information between view-specific representations, ensuring consistency between views and bridging semantic gaps from an information theory perspective. Furthermore, SMOM implements structure-driven adaptive fusion by combining gate strategies and graph neural networks, enabling the adaptive integration of complementary information. These components work together seamlessly to uncover sentiment patterns, achieving thorough and accurate monitoring of public opinions in social media. Experimental evaluations on social media datasets demonstrate SMOM’s superior performance in detecting nuanced public sentiments.
Keywords: Social media sentiment analysis; invariant representation learning; structure-driven adaptive fusion.
- [1] Z. Lian, L. Chen, L. Sun, B. Liu, and J. Tao, (2023) “Gcnet: Graph completion network for incomplete multimodal learning in conversation” IEEE Transactions on pattern analysis and machine intelligence 45(7): 8419–8432. DOI: 10.1109/TPAMI.2023.3234553.
- [2] G. Tu, B. Liang, R. Mao, M. Yang, and R. Xu. “Context or knowledge is not always necessary: A contrastive learning framework for emotion recognition in conversations”. In: Findings of the association for computational linguistics: ACL 2023. 2023, 14054–14067.
- [3] J. Gao, P. Li, A. A. Laghari, G. Srivastava, T. R. Gadekallu, S. Abbas, and J. Zhang, (2024) “Incomplete multiview clustering via semidiscrete optimal transport for multimedia data mining in IoT” ACM Transactions on Multimedia Computing, Communications and Applications 20(6): 1–20. DOI: 10.1145/3625548.
- [4] J. Gao, M. Liu, P. Li, A. A. Laghari, A. R. Javed, N. Victor, and T. R. Gadekallu, (2023) “Deep Incomplete Multiview Clustering via Information Bottleneck for Pattern Mining of Data in Extreme-Environment IoT” IEEE Internet of Things Journal 11(16): 26700–26712. DOI: 10.1109/JIOT.2023.3325272.
- [5] J. Gao, M. Liu, P. Li, J. Zhang, and Z. Chen, (2024) “Deep Multiview Adaptive Clustering With Semantic Invariance” IEEE Transactions on Neural Networks and Learning Systems 35(9): 12965–12978. DOI: 10.1109/TNNLS.2023.3265699.
- [6] H. Yang, X. Gao, J. Wu, T. Gan, N. Ding, F. Jiang, and L. Nie. “Self-adaptive context and modal-interaction modeling for multimodal emotion recognition”. In: Findings of the association for computational linguistics: ACL 2023. 2023, 6267–6281.
- [7] T. Meng, F. Zhang, Y. Shou, H. Shao, W. Ai, and K. Li, (2024) “Masked graph learning with recurrent alignment for multimodal emotion recognition in conversation” IEEE/ACM Transactions on Audio, Speech, and Language Processing: DOI: 10.1109/TASLP.2024.3434495.
- [8] Y. Tewel, O. Kaduri, R. Gal, Y. Kasten, L. Wolf, G. Chechik, and Y. Atzmon, (2024) “Training-free consistent text-to-image generation” ACM Transactions on Graphics (TOG) 43(4): 1–18. DOI: 10.1145/3658157.
- [9] M. Luo, H. Fei, B. Li, S. Wu, Q. Liu, S. Poria, E. Cambria, M.-L. Lee, and W. Hsu. “Panosent: A panoptic sextuple extraction benchmark for multimodal conversational aspect-based sentiment analysis”. In: Proceedings of the 32nd ACM International Conference on Multimedia. 2024, 7667–7676. DOI: 10.1145/3664647.36807.
- [10] S. Zou, X. Huang, and X. Shen. “Multimodal prompt transformer with hybrid contrastive learning for emotion recognition in conversation”. In: Proceedings of the 31st ACM International Conference on Multimedia. 2023, 5994–6003. DOI: 10.1145/3581783.3611805.
- [11] S. Liu, P. Gao, Y. Li, W. Fu, and W. Ding, (2023) “Multimodal fusion network with complementarity and importance for emotion recognition” Information Sciences 619: 679–694. DOI: 10.1016/j.ins.2022.11.076.
- [12] Q. Cheng, K. Wen, and X. Gu, (2022) “Vision-language matching for text-to-image synthesis via generative adversarial networks” IEEE Transactions on Multimedia 25: 7062–7075. DOI: 10.1109/TMM.2022.3217384.
- [13] K. Yang, H. Xu, and K. Gao. “Cm-bert: Cross-modal bert for text-audio sentiment analysis”. In: Proceedings of the 28th ACM international conference on multimedia. 2020, 521–528. DOI: 10.1145/3394171.3413690.
- [14] T. Yu, H. Gao, T.-E. Lin, M. Yang, Y. Wu, W. Ma, C. Wang, F. Huang, and Y. Li. “Speech-text pre-training for spoken dialog understanding with explicit cross-modal alignment”. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023, 7900–7913.