Can ChengThis email address is being protected from spambots. You need JavaScript enabled to view it.
School of Foreign Languages, Zhengzhou University of Science and Technology, Zhengzhou 450064 China
Received: December 31, 2025 Accepted: January 31, 2026 Publication Date: February 26, 2026
Copyright The Author(s). This is an open access article distributed under the terms of the Creative Commons Attribution License (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are cited.
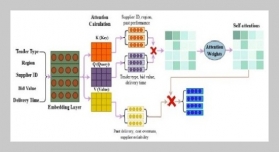
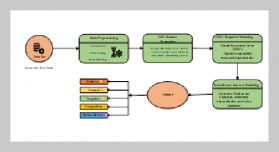
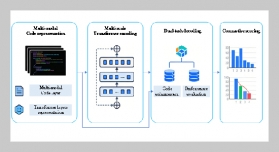
Source-text transfer errors (STTEs) are pervasive in second language (L2) argumentative writing, particularly when learners integrate translated content from their first language (L1) into L2 drafts. These errors undermine argument coherence, linguistic accuracy, and academic rigor, yet traditional assessment methods lack the granularity and timeliness to identify and address them proactively. To bridge this gap, this study proposes a curriculum-embedded deep analytics framework that combines multitask BERT (MT-BERT) with just-in time (JIT) micro-interventions to predict STTEs in L2 argumentative writing. First, we construct a large-scale annotated corpus of L2 English argumentative drafts ( n = 8,236 ) paired with their L1 (Chinese) source texts, labeling STTEs across five categories: lexical transfer, syntactic transfer, semantic distortion, pragmatic misalignment, and logical inconsistency. Second, we develop an MT-BERT model that jointly learns STTE prediction, L1-L2 semantic alignment, and argumentative structure classification, outperforming single-task BERT, RoBERTa, and traditional machine learning baselines. Experimental results show that the proposed MT-BERT achieves 0.892 F1-score for STTE detection and 0.876 for error category classification, with significant improvements in handling low-resource error types. Third, we design JIT micro-interventions tailored to predicted STTEs, delivering targeted feedback during the writing process via a curriculum-integrated platform. Aquasi-experimental study demonstrates that the framework reduces STTE occurrence by 41.3% and improves writing quality (measured by holistic scores) by 15.7% compared to conventional feedback methods. This research contributes to L2 writing analytics by (1) developing a fine-grained STTE annotation schema and corpus, (2) proposing a multitask deep learning architecture optimized for curriculum-embedded scenarios, and (3) validating the efficacy of JIT micro-interventions in real-world L2 writing instruction. The framework offers scalable, adaptive support for L2 learners and actionable insights for instructors, advancing the integration of natural language processing (NLP) into formative assessment practices.
Keywords: L2 Argumentative Writing; Source-Text Transfer Errors; Multitask BERT; Curriculum-Embedded Analytics; Just-in-Time Micro-Interventions; Natural Language Processing
[1] M. A. Farsani, P. Stapleton, and H. R. Jamali, (2025) “Charting L2argumentative writing: A systematic review" Journal of SecondLanguageWriting68:101208. DOI: 10.1016/j.jslw.2025.101208.
[2] Y. Zheng and J. S. Barrot, (2024) “Syntactic complexity in second language (L2) writing: Comparing students’ narrative and argumentative essays" System 123: 103342. DOI: 10.1016/j.system.2024.103342.
[3] E.Saridaki, (2025) “A comparative Study between Translation Problems and Translation Errors" Journal Of Arts Humanities And Social Sciences 4(3): 1–4. DOI: 10.5281/zenodo.14983891.
[4] R. Wisudawanto and K. Zaini, (2025) “Translating Meaning and Intention: Error Analysis of Indonesian Children Fairy Tale Subtitles on YouTube" New Lan guage Dimensions 6(1): 61–70. DOI: 10.26740/nld.v6n1.p61-70.
[5] H. Li, Z. Li, X. Wang, M. Ibrar, and X. Zhu, (2024) “Multi-keyword Ciphertext Sorting Search Based on Con formation Graph Convolution Model and Transformer Network in English Education" International Journal of Network Security 26(4): 555–564. DOI: 10.6633/ IJNS.202407_26(4).03.
[6] B. K. Güldal and A. Ö. Tarakcıo˘glu, (2025) “A Suggestion of Translation Quality Assessment Model: Translation Errors and Preferences in Research Article Abstracts in the Context of Academic Translation." Turkish Studies-Language & Literature 20(1): DOI: 10.7827/TurkishStudies.77984.
[7] F. J. Hoo, A. H. S. M. Yusuf, N. M. Ayob, S. Maulan, andA.I.Jailani, (2025) “Analysing Translation Errors of Higher Education Learners Using MQM and ISO 17100: Implications for Language Education" Journal of Re search, Innovation, and Strategies for Education (RISE) 2(1): DOI: https: //doi.org/10.70148/rise.20.
[8] T.L.N.Nguyen,D.T.B.Dang,H.T.K.Nguyen,etal., (2025) “Vietnamese-English Translation Errors and Pedagogical Implications in the Digital Age: A Case of English Major Students at a University in Vietnam" Theory and Practice in Language Studies 15(5): 1710–1721. DOI: 10.17507/tpls.1505.36.
[9] L. Gao and T. Dong. “Research on Automatic Detection and Correction of English Translation Errors Based on Machine Learning”. In: 2025 International Conference on Digital Analysis and Processing, Intelli gent Computation (DAPIC). IEEE. 2025, 552–556. DOI: 10.1109/DAPIC66097.2025.00108.
[10] A. N. Firdausi, T. Setiawan, D. A. Jati, and H. Rahmi, (2025) “Unraveling Errors in Poetry: A Translation Qual ity Assessment of Sapardi Djoko Damono’s Sajak Orang Gila" LingTera 12(2): DOI: 10.21831/lt.v12i2.83155.
[11] Y. Zhang, D. Mei, H. Luo, C. Xu, and R. T.-H. Tsai, (2025) “Smutf: Schema matching using generative tags and hybrid features" Information Systems: 102570. DOI: 10.1016/j.is.2025.102570.
[12] B. Chen, S. Shi, Y. Luo, B. Xu, R. Cai, and Z. Hao. “Track-SQL: Enhancing Generative Language Models with Dual-Extractive Modules for Schema and Context Tracking in Multi-turn Text-to-SQL”. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025, 10690–10708. DOI: 10.18653/v1/2025.naacl-long.536.
[13] R. Guo, G. Gong, and F. Jiang, (2025) “DMBT Decou pled Multi-Modal Binding Transformer for Multimodal Sentiment Analysis" Electronics 14(21): 4296. DOI: 10.3390/electronics14214296.
[14] J. Yu, L. Zhao, S. Yin, and M. Ivanovi´c, (2024) “News recommendation model based on encoder graph neural net work and bat optimization in online social multimedia art education" Computer Science and Information Systems 21(3): 989–1012. DOI: 10.2298/CSIS231225025Y.
[15] R. Xu, G. Li, and V. S. Sheng. “Enhancing ChatGPT 4o’s Automated Programming Assignment Grading and Feed back with Human-in-the-LoopRefinement”. In: International Conference on Intelligent Computing. Springer. 2025, 469–481. DOI: 10.1007/978-981-96 9884-4_39.
[16] E. Ovando-Becerril and H. Calvo. “A Metaphorical Text Classifier to Compare the Use of RoBERTa-Large, RoBERTa-Base and BERT-Base Uncased”. In: Interna tional Workshop on Artificial Intelligence and Pattern Recognition. Springer. 2023, 248–259. DOI: 10.1007/ 978-3-031-49552-6_22.
[17] L. Xu, S. Alnegheimish, L. Berti-Equille, A. Cuesta Infante, and K. Veeramachaneni, (2025) “Single word change is all you need: using LLMs to create synthetic training examples for text classifiers" Expert Systems 42(8): e70079. DOI: 10.1111/exsy.70079.
[18] J. Xu and Q. Du, (2020) “TextTricker: Loss-based and gradient-based adversarial attacks on text classification models" Engineering Applications of Artificial Intelligence 92: 103641. DOI: 10.1016/j.engappai.2020. 103641.
[19] O. M. Alyasiri, Y.-N. Cheah, H. Zhang, O. M. Al Janabi, and A.K.Abasi,(2025)“Textclassification based on optimization feature selection methods: a review and future directions" Multimedia Tools and Applications 84(15): 14187–14233. DOI: 10.1007/s11042-024-19769 6.
[20] T. Ü. ¸Sen, M. C. Yakit, M. S. Gümü¸s, O. Abar, and G. Bakal, (2025) “Combining N-grams and graph convolution for text classification" Applied Soft Computing 175: 113092. DOI: 10.1016/j.asoc.2025.113092.
We use cookies on this website to personalize content to improve your user experience and analyze our traffic. By using this site you agree to its use of cookies.